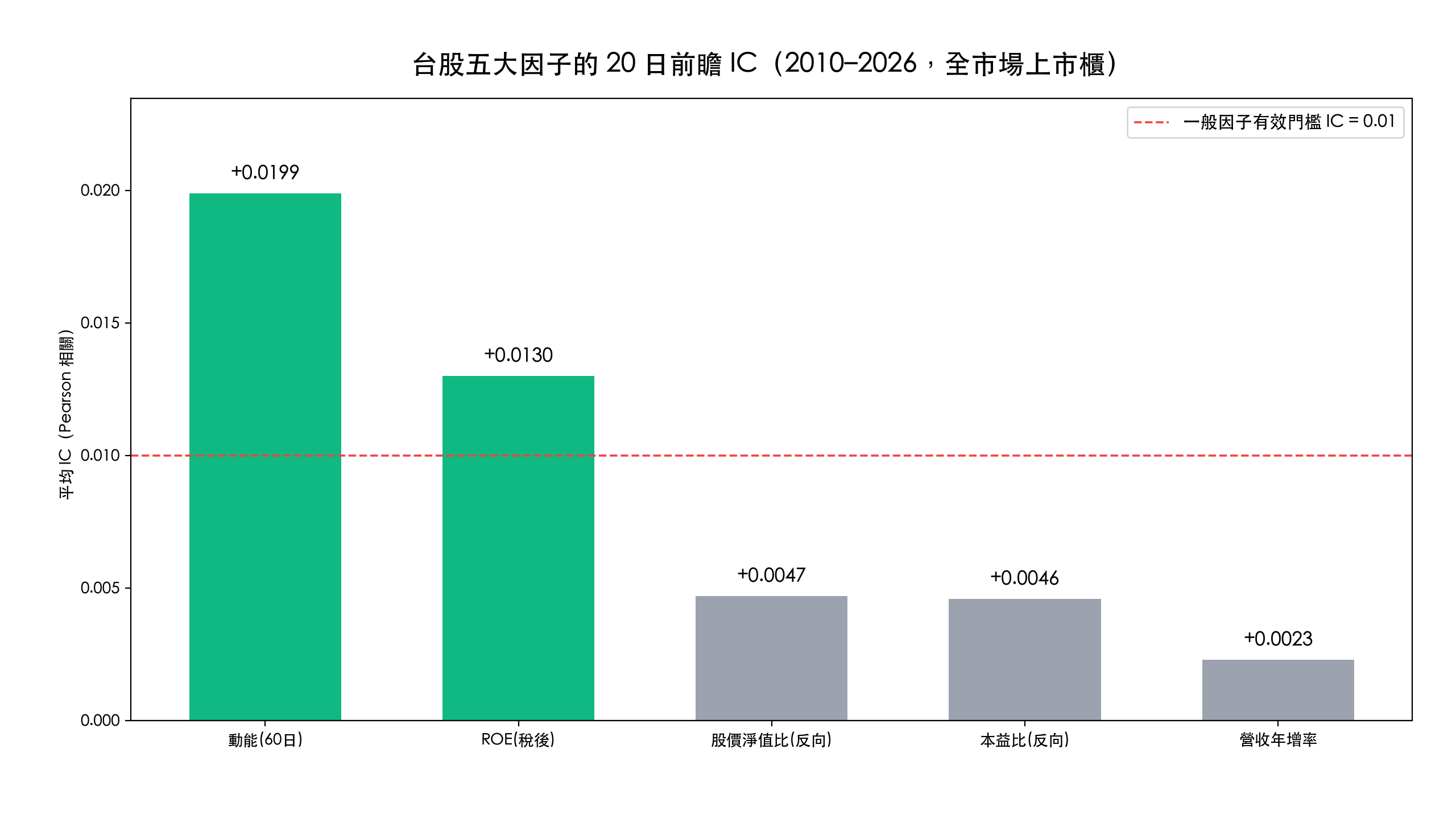
Information Coefficient(IC,資訊係數)是因子預測值與未來實際報酬之間的相關係數,用來把「這個選股因子到底有沒有預測力」量化成一個可比較的數字。 它回答的問題是:我今天用這個因子把股票排序,這個排序對未來報酬有沒有預測力?IC 越接近正向,代表因子排越前面的股票、未來報酬傾向越高。下表是我們用 finlab 實測台股 2010–2026 全市場上市櫃、20 個交易日(約一個月)前瞻 IC 的結果。
台股五大因子的真實 IC(關鍵數字)
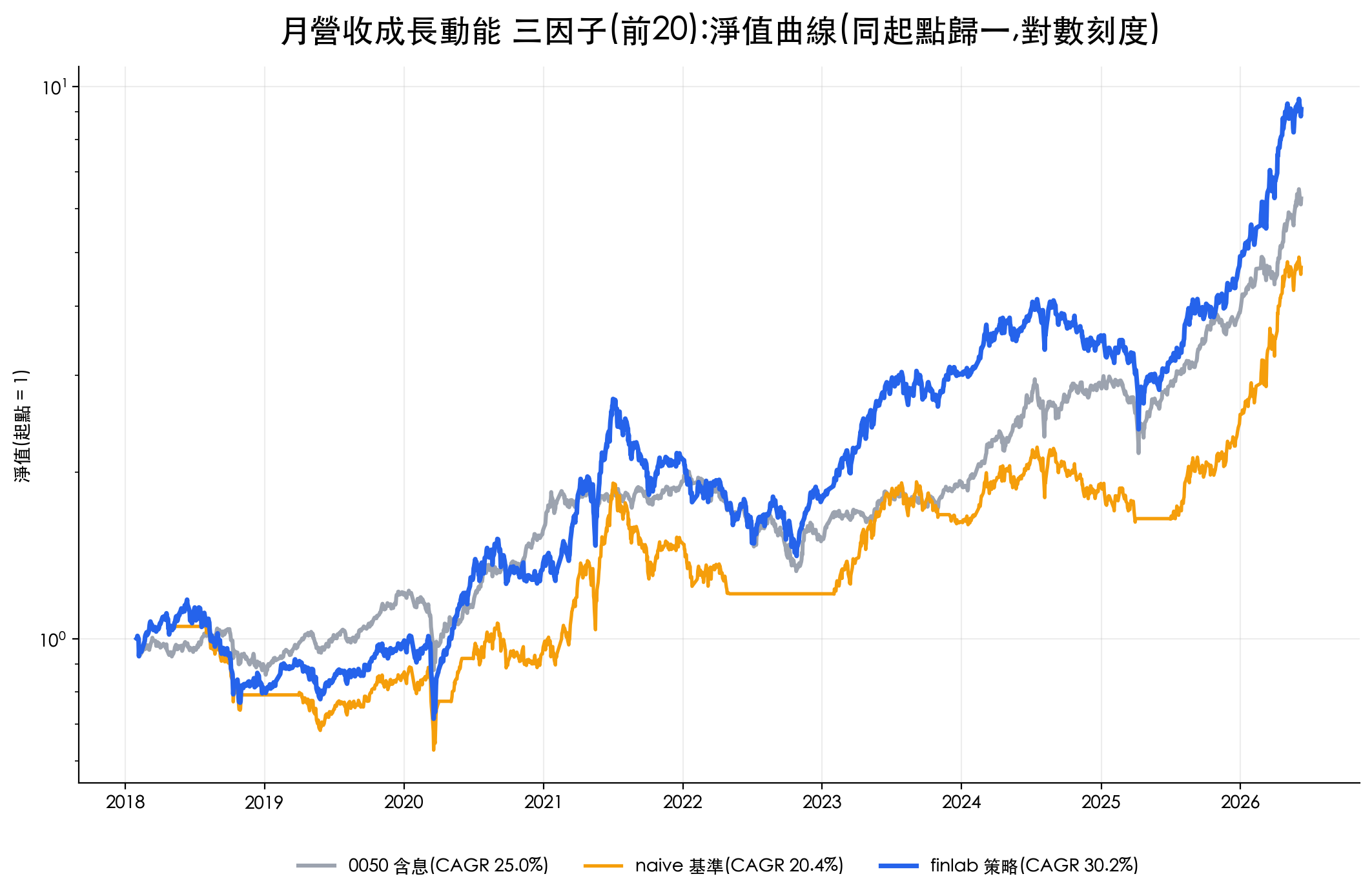
一句話:IC 因子分析就是用「因子值與未來報酬的相關係數」幫每個選股因子打分,越過 0.01 代表單因子可用。 本文用 finlab 實測台股 2010–2026,動能因子 20 日前瞻 IC 約 +0.0199、ROE 約 +0.0130 都過門檻,價值類與營收年增則偏低。注意 finlab 的 ic() 算的是 Pearson IC;若改算排序版的 Rank IC(Spearman),價值因子的分數會明顯升高、動能反而下降,本文的因子強弱排序會翻盤(見下方計算口徑段)。
| 因子 | 平均 IC | IC IR | 正值期間佔比 | 是否過 0.01 門檻 |
|---|---|---|---|---|
| 動能(過去 60 日報酬) | +0.0199 | 0.165 | 59.5% | ✅ |
| ROE(稅後) | +0.0130 | 0.163 | 58.9% | ✅ |
| 股價淨值比(反向) | +0.0047 | 0.063 | 54.8% | ❌ |
| 本益比(反向) | +0.0046 | 0.099 | 57.3% | ❌ |
| 營收年增率 | +0.0023 | 0.079 | 47.7% | ❌ |
資料來源:finlab factor_analysis.ic,全市場上市櫃、2010-01 至 2026-06、20 日前瞻、Pearson 相關。動能與 ROE 兩個因子越過「一般因子 IC > 0.01」的實務門檻,價值類(本益比、股價淨值比)與營收年增在這段期間的單因子 IC 偏低。這正是 IC 的用處:在做出任何回測之前,先用一個數字判斷因子值不值得用。
IC 是什麼?為什麼比回測曲線更該先看
IC 是因子值與「未來」報酬的相關係數。和一般相關係數的數學定義相同,差別在於它帶有時間先後:先有今天的因子分數、再對應未來一段時間的報酬,因此衡量的是「預測力」而不是「同期關聯」。實務上 IC 通常逐期計算(例如每天或每月,對全市場算一次因子分數與下一期報酬的相關係數),再取一段時間的平均與波動。
在量化交易的研發流程裡,IC 把「因子是否有效」這件事量化成一個可比較的數字,而不是靠回測曲線好不好看來判斷。回測曲線漂亮,可能只是剛好選到一兩支暴漲股;IC 是全市場、逐期的統計,較難被少數樣本扭曲。Grinold 在 Grinold (1989) 提出的「主動管理基本法則」更把它寫成一條關係式:資訊比率 IR ≈ IC × √(投資廣度),意思是因子預測力(IC)與押注次數(breadth)共同決定一個策略長期能創造多少風險調整後報酬。換句話說,因子的預測力(IC)是策略長期獲利能力的源頭之一,這也是它值得在動筆寫策略前就先量化的原因。
IC 多少算好?用真實數字校準
實務經驗常說:一般因子的 IC 盡量大於 0.01,機器學習模型的綜合 IC 最好大於 0.05。從上面的台股實測可以看到,單一因子的月頻 IC 普遍就落在 0.002 到 0.02 之間,這是正常的,不要被「相關係數只有 0.02」嚇到。因子預測力本來就微弱,量化的獲利來自把大量微弱但穩定的訊號,透過分散的押注累積起來(這正是 Grinold 法則裡 breadth 的角色)。
所以正確的讀法是:動能的 0.0199 與 ROE 的 0.0130 是「可用」的單因子;要把綜合 IC 推到 0.05 以上,得靠多個低相關因子的組合,而不是把單因子的門檻訂得不切實際。把多個因子組成策略的完整流程,可以參考因子分析實戰:3 因子選股與多因子選股策略教學,IC 在那裡扮演的就是篩選與排序因子的角色。
怎麼用 finlab 算 IC?
finlab 內建 factor_analysis.ic,傳入因子與還原股價,就會回傳逐期 IC 的時間序列:
顯示程式碼
from finlab import data
from finlab.tools.factor_analysis import ic
adj = data.get('etl:adj_close')
# 動能因子:過去 60 個交易日的報酬
momentum = adj / adj.shift(60) - 1
# 計算 20 日(約一個月)前瞻 IC 的時間序列
ic_series = ic(momentum, adj, days=[20])
print(ic_series.mean()) # 平均 IC ≈ 0.0199第一次取資料時,finlab 會自動引導登入,照套件指示操作即可。要一次比較多個因子,把它們放進迴圈分別計算平均 IC 就能得到本文開頭那張長條圖:
顯示程式碼
factors = {
'動能(60日)': momentum,
'ROE(稅後)': data.get('fundamental_features:ROE稅後'),
'本益比(反向)': -data.get('price_earning_ratio:本益比'),
'股價淨值比(反向)': -data.get('price_earning_ratio:股價淨值比'),
'營收年增率': data.get('monthly_revenue:去年同月增減(%)'),
}
for name, f in factors.items():
s = ic(f, adj, days=[20]).iloc[:, 0].dropna()
print(name, round(s.mean(), 4), 'IR', round(s.mean() / s.std(), 3))本益比與股價淨值比取負號,是因為「比值越低越便宜」,要讓因子方向與報酬同向。
IC 不能只看平均:時間穩定度
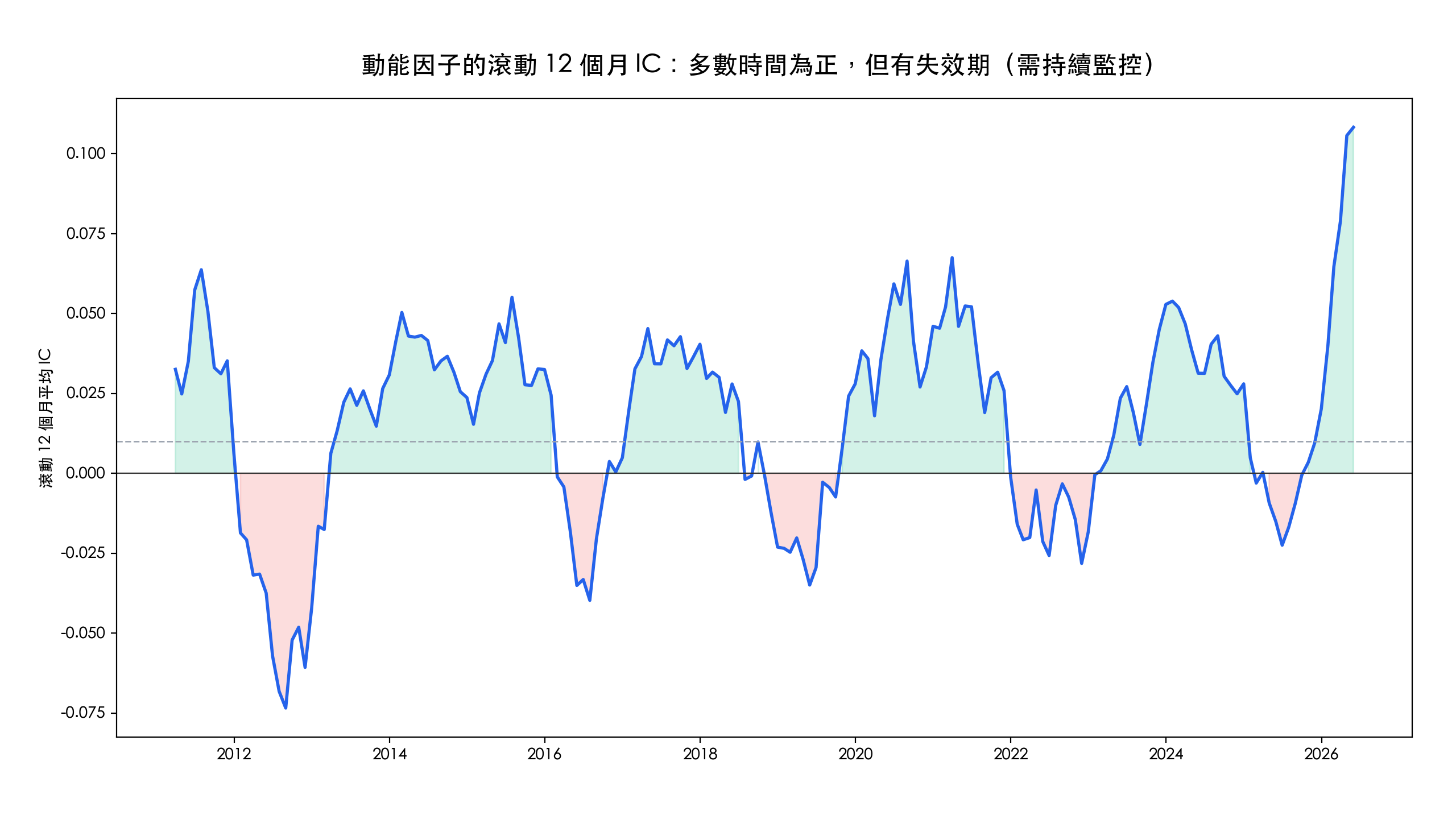
平均 IC 為正只是及格線,更重要的是它穩不穩。把動能因子的月度 IC 畫出來,可以看到它逐月上下波動,但累積 IC 長期穩定向上,代表這個訊號不是靠某一段行情撐起來的。
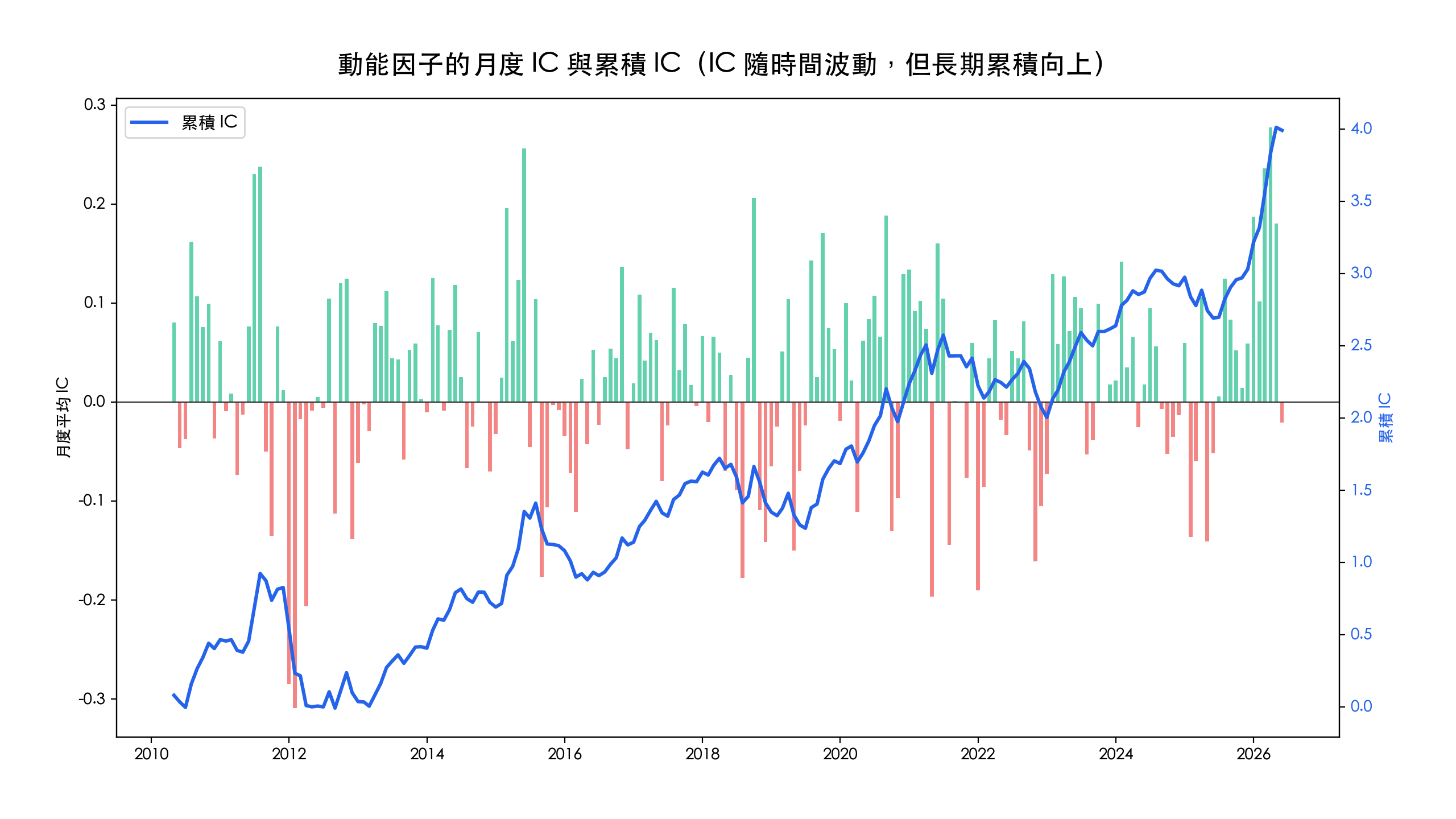
衡量穩定度的常見方式是 IC IR(IC 的平均除以標準差),上表動能與 ROE 的 IC IR 都在 0.16 左右。再把 IC 取滾動 12 個月平均,更能看出因子的「失效期」:動能因子在 2010–2026 約有 68.9% 的時間滾動 IC 為正,但也存在幾段轉負的區間,這就是需要持續監控、而非設定一次就放著不管的理由。
分位數檢驗:IC 背後的單調性
IC 是一個總結數字,搭配十分位前瞻報酬看會更踏實。把每個再平衡日的股票,依動能因子分成十等分,再看各分位未來 20 日的平均報酬:
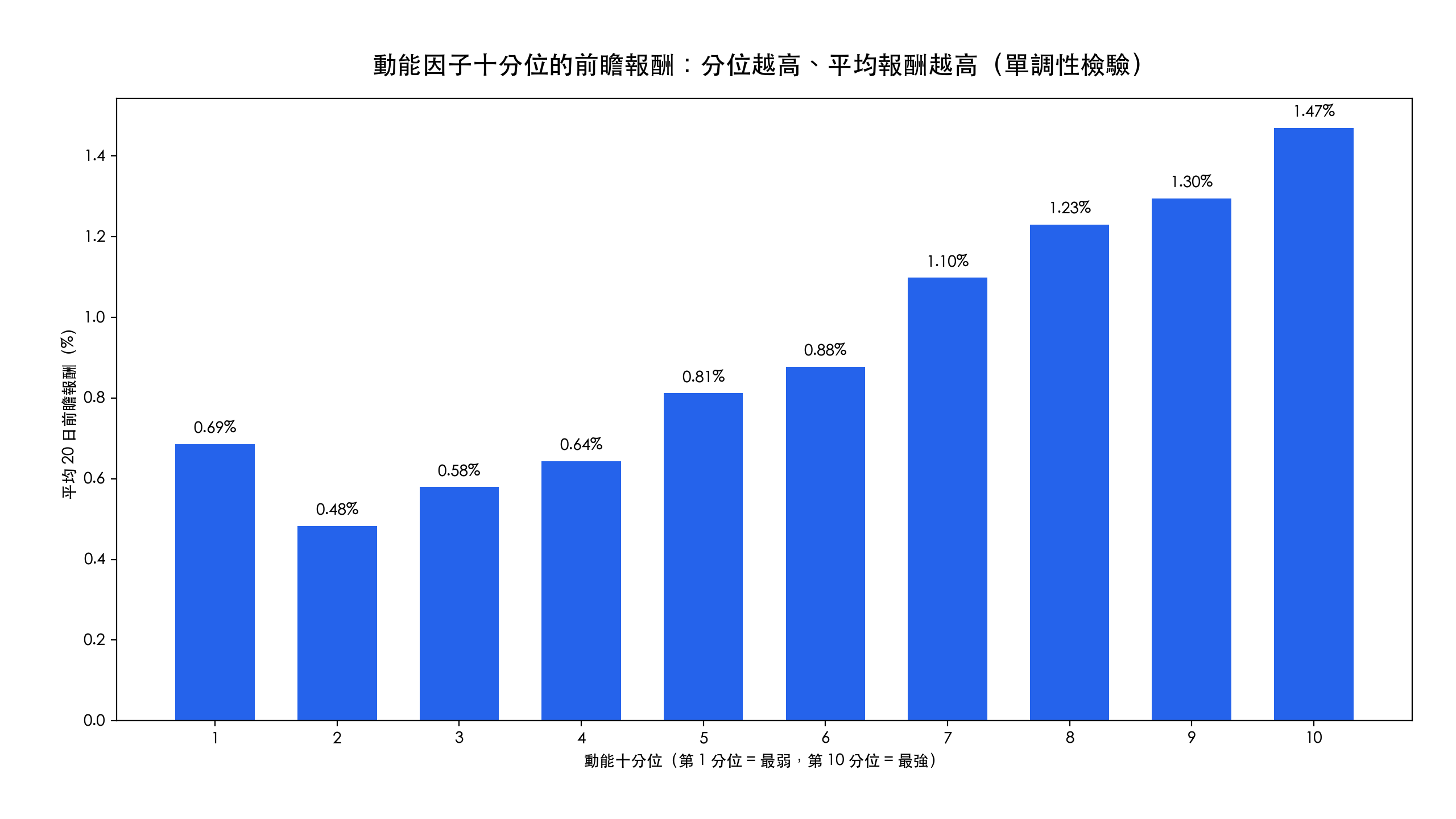
第 2 分位到第 10 分位呈現清楚的單調遞增,最強分位(+1.47%)比最弱那幾組高出約 0.78 個百分點。單調性比單一 IC 數字更能說服人:整條排序由弱到強都帶有資訊,代表因子的效果遍及全市場,而非只集中在少數極端股票。如果一個因子 IC 為正、分位卻雜亂無章,那這個訊號就值得懷疑。
IC 會隨持有期改變嗎?
同一個因子,用不同的持有期(前瞻天數)算 IC,結果可能差很多。把動能與 ROE 的 IC 分別在 5、10、20、60、120 個交易日的前瞻期算出來:
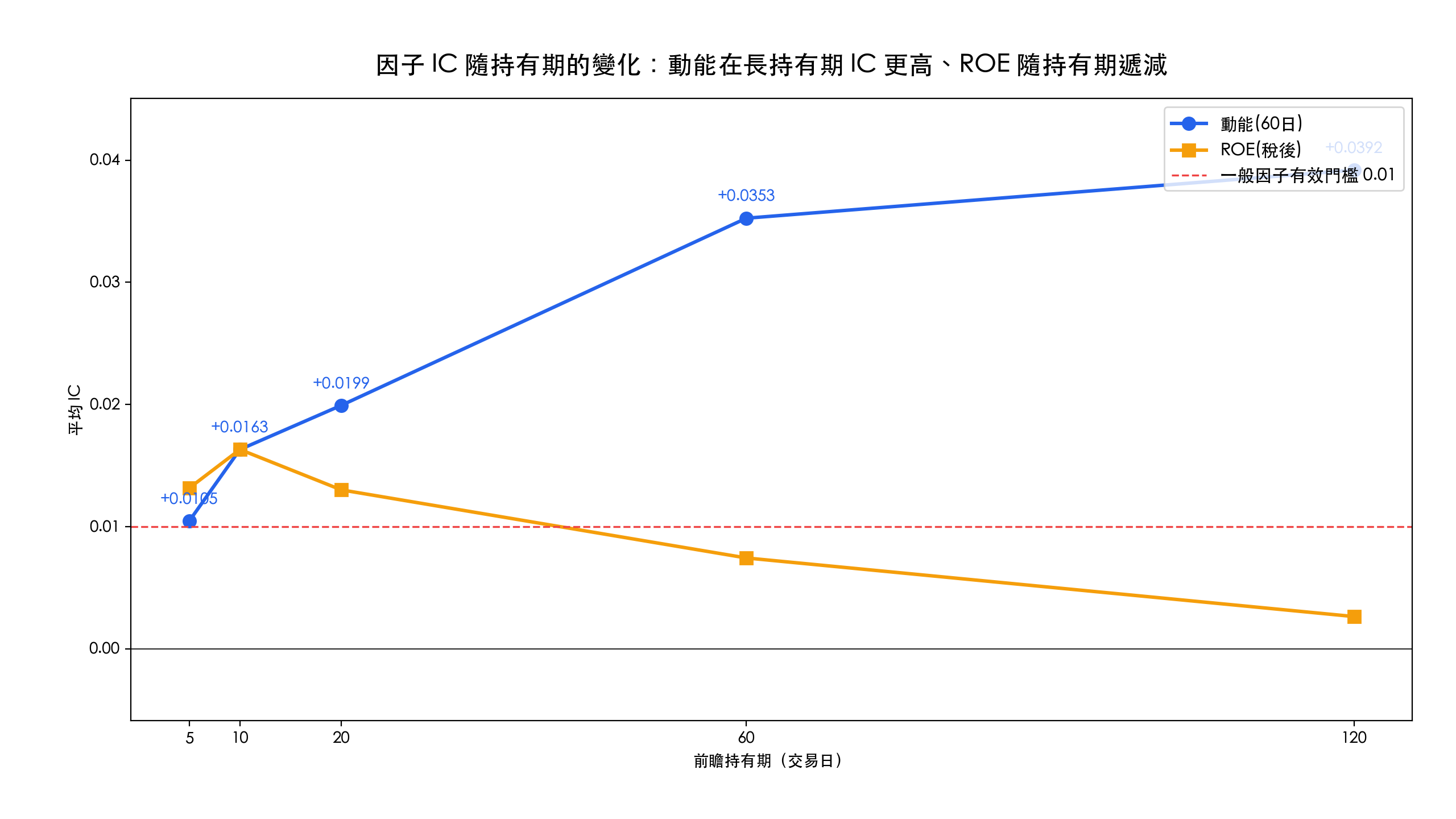
動能因子的 IC 隨持有期拉長而升高,從 5 日的約 0.011 一路升到 120 日的約 0.039,是偏中長期的訊號;ROE 則相反,在 10 日內最強(約 0.016),之後隨持有期遞減,到 120 日只剩約 0.003,屬於短期較有效的品質訊號。這代表同一個因子的 IC 高低,和你打算持有多久綁在一起:研究因子時必須連持有期一起定義,否則容易誤判因子的強弱,這也是為什麼選好因子之後,還要選對再平衡頻率。
IC 最重要的價值:避免過擬合
當你回測「每月持有 10 檔股票」時,一年的樣本數只有 12 × 10 = 120 個。樣本這麼少,只要選到一兩支暴漲股,回測績效就會異常漂亮。問題是你永遠分不清,自己究竟是:
- 發現了某個現象,捕捉到真的會上漲的股票,還是
- 為了套住已知會上漲的股票,反推設計出這些條件。
兩者都能讓回測好看,但樣本外(實單)結果天差地別。Bailey, Borwein, López de Prado & Zhu (2014) 證明:只要你反覆嘗試足夠多組策略設定,幾乎一定能挑出一條樣本內夏普很高、樣本外卻沒用的曲線,他們把這種風險量化成「回測過擬合機率」。IC 的好處正在於它是全市場監測:你的樣本一下子變成上市櫃近兩千檔,還能用滾動方式增加樣本數,大幅降低被少數幸運股誤導的機率。想從另一個角度量化過擬合風險,可以搭配用回測過擬合機率判斷策略真實力:IC 看的是因子在全市場的預測力,過擬合機率評估的是這組回測有多大可能只是運氣,兩者互補。
機器學習選股更該用 IC 把關。如果用基因演算法暴力列舉參數,隨時都能生出回測漂亮的策略,但那多半是過擬合。正確做法是先把模型輸出的綜合 IC 調到夠高、且在樣本外穩定,再來談回測。實際把 IC 用在 ML 選股的流程,可以參考用 Qlib 與 finlab 訓練台股 AI 選股模型與機器學習產生交易訊號的正確方法。
計算口徑與限制
- 相關係數類型:finlab
factor_analysis.ic用的是 Pearson 相關。Pearson 對極端值較敏感(例如本益比的離群值),改用排序後再算相關的 Rank IC(Spearman)結論可能不同:在台股上,價值因子的 Rank IC 明顯高於 Pearson、動能則相反,本文的因子強弱排序若改看 Rank IC 會翻盤,完整實證見 Rank IC vs Pearson IC 的台股對照。 - 前瞻期間:本文用 20 個交易日(約一個月)。換成 5 日或 60 日,IC 的數值與最佳因子可能改變,因子的「最適持有期」本身就是要研究的問題。
- 樣本:全市場上市櫃,未額外排除全額交割、KY 股或低流動性個股;嚴謹的因子研究會再加流動性過濾,避免回測買得到、實單買不到。
- IC 不是報酬:IC 衡量的是預測力,不是策略淨報酬,因此這裡不涉及手續費、證交稅與滑價;那些要在把因子做成策略、進入回測時才計入。
- 數字可重現:上表數字由全市場資料逐期計算後平均,使用相同資料窗重跑即可重現。
常見問題(FAQ)
Information Coefficient(IC)是什麼?
IC 是因子預測值與未來實際報酬之間的相關係數,用來衡量一個選股因子對未來報酬的預測力。它把「這個因子到底有沒有用」量化成一個數字,正值代表因子排序與未來報酬同向。在量化交易裡,IC 是驗證因子與監控模型穩定性的核心指標。
IC 多少算好?
一般因子的 IC 盡量大於 0.01,機器學習模型的綜合 IC 最好大於 0.05。以本文台股實測為例,動能(0.0199)與 ROE(0.0130)越過 0.01,價值類與營收年增則偏低。單因子月頻 IC 落在 0.002–0.02 是正常的,重點是 IC 長期是否維持正向且穩定,而非單一數值高低。
IC 怎麼計算?
把因子分數與下一期實際報酬計算相關係數,通常逐期(例如每月)算一次,再取一段時間平均。實作上用 finlab 的 factor_analysis.ic,傳入因子與 etl:adj_close,呼叫 .mean() 取得平均 IC,本文程式碼即為最小範例。
IC 和 Rank IC 有什麼不同?
IC 一般指 Pearson 相關,Rank IC 指排序後計算的 Spearman 相關。Rank IC 對極端值較不敏感,因子分布偏態(如本益比)時常用 Rank IC 佐證。finlab 內建的 ic() 計算的是 Pearson 版本。
什麼是 Rank IC?該用 IC 還是 Rank IC?
Rank IC 是先把每期的因子值與未來報酬各自轉成排序名次,再算兩組名次的相關係數(Spearman)。它對離群值較不敏感,因此分布偏態的因子(如本益比、股價淨值比)通常用 Rank IC 才看得準。實務上兩者一起看:本文的 Pearson IC 排序在台股上改看 Rank IC 會翻盤,價值因子的 Rank IC 明顯高於 Pearson、動能則相反,完整對照見Rank IC vs Pearson IC 的台股對照。
IC 因子分析在量化交易裡用來做什麼?
用來在回測之前先篩掉沒有預測力的因子。對全市場逐期計算因子分數與未來報酬的 IC,過 0.01 且 IC IR 為正、滾動 IC 多數時間在零以上的因子才值得納入候選,再用多個低相關因子組合把綜合 IC 推高。它是量化交易完整指南裡的研發流程中,篩選與排序因子的核心步驟。
IC 多少才能拿來做策略?
沒有絕對門檻,但實務上單因子 IC 過 0.01、且 IC IR(穩定度)為正、滾動 IC 多數時間在零以上,就值得納入候選。最終要靠多個低相關因子組合,把綜合 IC 推高,再進入回測與風控。
IC 和一般相關係數有什麼不同?
數學定義相同,差別在「比的是什麼」。IC 特指因子值與未來報酬的相關係數,帶有時間先後的預測意涵,且通常在全市場逐期計算後取平均。一般相關係數沒有這層時序限制,因此 IC 更貼近實單會遇到的樣本外預測情境。
延伸閱讀
- 量化交易完整指南
- 因子分析實戰:3 因子選股
- 多因子選股策略教學:營收+動能+ROE+低波
- 台股股票選股器
- 用回測過擬合機率判斷策略真實力
- 台股選股回測:單因子與複合策略比較
- 用 Qlib 與 finlab 訓練台股 AI 選股模型
- 機器學習產生交易訊號的正確方法
- 量化名詞詞彙表:IC 定義
投資警語:本文為量化交易方法與工具的教學說明,所有數據與範例僅供研究參考,不構成投資建議。投資前請自行評估風險。
最後更新:2026-06|IC 計算區間:2010-01 至 2026-06、20 日前瞻、全市場上市櫃|作者:FinLab 量化研究團隊(經量化研究員審閱)
FinLab AI
想建立自己的策略?
用自然語言描述你的選股想法,AI 自動驗證、回測、給你答案
免費開始