Qlib 是微軟開源的 Python AI 量化投資研究平台,把資料處理、特徵生成、模型訓練、回測與下單決策串成一條龍。 這篇是 Qlib 的台股動手實作:用 finlab[qlib] 三步驟把 Qlib 接上台股,跑出可檢查的 AI 選股回測。Qlib 內建十餘種機器學習與深度學習模型範例;它最大的門檻是預設資料只有中國(滬深 300)與美股,沒有台股,而且要自己把資料轉成 Qlib 的二進位格式、處理台股「一張 1000 股、漲跌停 10%」這些市場規則。本文把重心放在實作流程,示範把資料倒進 Qlib(q.dump())、生成 Alpha158 特徵(q.alpha())、用 q.get_models() 一鍵訓練 LightGBM、XGBoost 等模型來回測。
Qlib 關鍵數字
| 項目 | 內容 |
|---|---|
| 開發者 | 微軟亞洲研究院(Microsoft),GitHub 開源 |
| 語言 | Python |
| 內建市場資料 | 中國(滬深 300)、美股;預設不含台股 |
| 特徵資料集 | Alpha158(158 個價量特徵)、Alpha360(360 個) |
| 內建模型 | 十餘種,含梯度提升樹(LightGBM/XGBoost/CatBoost)與深度學習(TabNet/DNN/LSTM 延伸) |
| 涵蓋流程 | 資料 → 特徵 → 建模 → 回測 → 下單決策(一條龍) |
| 台股支援 | 透過 finlab[qlib] 接上(見下方台股實作) |
Qlib 的三個特色
內建多種 AI 演算法模型
Qlib 最有價值的地方在於降低了使用 AI 演算法的門檻。套件內有十幾個機器學習與深度學習在股票交易上的應用範例,許多是相對新穎的架構,且都已模組化,換資料、調參數就能用。其中不少屬於 Self-attention 一類,例如 TRA(Temporal Routing Adaptor)把 LSTM 延伸成能學習多種策略風格的模型。想先理解 LSTM 在股價序列上的基本用法,可以參考我們用 LSTM 解析 K 線預測台股的實作。GitHub 上除了程式碼,也在 qlib/examples/benchmarks 附上對應論文,方便開發者追到方法本身。
現成的特徵資料集
AI 訓練的第一步是準備特徵,而生成好特徵並不容易。Qlib 基於股市資料建構了 Alpha158 與 Alpha360 兩套特徵集,把價量資料展開成大量訊號:
| 特徵集 | 特徵數 | 特性 | 記憶體需求 |
|---|---|---|---|
| Alpha158 | 158 | 日常研究主力,價量訊號為主 | 全台股日頻偏大,週頻可省約 80% |
| Alpha360 | 360 | 更細緻,訊號更多 | 展開後常需上百 GB,需高階硬體 |
Workflow 與 Recorder 訓練管理
Workflow 層負責模型的訓練與回測,從尋找獲利因子(Alpha)與風險因子,一路到資產配置、選股、下單決策。搭配的 Recorder 流程管理器則用來記錄與儲存訓練過程與結果;AI 模型訓練時間長、偶爾中斷,Recorder 能讓你從中斷處續跑,不必從頭再來。
Qlib 背後的研究脈絡
Qlib 把近年「機器學習做資產定價」的研究成果工程化成一套可重複使用的平台。微軟團隊在 Yang et al. (2020) 提出 Qlib,定位為「AI 導向的量化投資平台」,目標是把資料處理、特徵工程、模型訓練到回測的流程標準化,讓不同模型能在同一套資料與評估標準下公平比較。
機器學習能否真的改善選股,學界已有具規模的證據。Gu, Kelly & Xiu (2020) 在 Review of Financial Studies 用美股數十年資料比較各種方法,發現樹模型與神經網路在預測股票報酬上,普遍優於傳統線性因子模型,主因是能捕捉因子之間的非線性與交互作用,這正是 Qlib 內建 LightGBM 與深度學習模型的理由。不過同一份研究也提醒:機器學習的優勢來自「組合大量弱訊號」,對資料品質與防止過擬合的要求很高,這也是後面實作會特別強調樣本內外切分與交易成本的原因。
為什麼 Qlib 預設跑不了台股
Qlib 是通用型框架,特徵幾乎都用價格序列製作,預設市場綁定滬深 300 與美股。要在台股使用,得自己處理兩件麻煩事:一是把台股資料轉成 Qlib 自家的 .bin 二進位格式(含日曆、商品清單、還原因子),二是設定台股的市場規則,包括成交單位一張 1000 股、漲跌停 10%、以收盤價成交。這兩件事工程量都不小,也是很多人卡關的地方。finlab 的 finlab.ml.qlib 模組把這兩件事包成函式,所以你不用碰 Qlib 底層。
安裝:一行帶起 finlab + Qlib
顯示程式碼
pip install 'finlab[qlib]'模型後端是選用的,需要哪個再裝哪個(Colab 多半已預裝):
顯示程式碼
pip install lightgbm xgboost catboost
pip install ta-lib桌機安裝 TA-Lib 用 conda install conda-forge::ta-lib;Colab 上則用 pip install ta-lib-bin。第一次跑到需要資料時,finlab 會自動引導你登入,照指示操作即可,程式碼不需要手動填任何 token。
三行:把台股倒進 Qlib、生成 Alpha158 特徵
顯示程式碼
from finlab.ml import qlib as q
q.dump() # 把台股資料轉成 Qlib 格式(第一次執行較久)
q.init() # 以台股設定初始化 Qlib(一張 1000 股、漲跌停 10%、收盤價成交)
f158 = q.alpha("Alpha158") # 生成 158 種價量特徵q.dump() 會把台股的開高低收、成交量與還原因子寫成 Qlib 的 .bin 資料庫;q.init() 等同台股版的 qlib.init(),自動把成交單位設成 1000 股、漲跌停 0.1、成交價設為收盤價。q.alpha() 支援 Alpha158 與 Alpha360 兩種特徵集(差異見上方表格)。
Alpha158 在全台股、日頻展開後資料量很大。把頻率改成「週」可以省下約 80% 的資料量,在 50GB RAM 的環境(如 Colab Pro)勉強跑得動:
顯示程式碼
from finlab.ml import label as mll
from finlab.ml import feature as mlf
features = mlf.combine({
'qlib': f158,
}, resample='W')
labels = mll.return_percentage(features.index, period=2)mlf.combine 把特徵重採樣到週頻並對齊索引,mll.return_percentage 生成「未來 2 期報酬率」當訓練標籤。實務上 Alpha158 裡的 VWAP0 欄位會整欄是空值,訓練前先移除(或用 mlf.combine 自行補一份 VWAP):
顯示程式碼
features = features.drop('VWAP0', axis=1)一鍵叫出所有 Qlib 模型來訓練
finlab 把 Qlib 的模型工廠包成 q.get_models(),回傳一整批可直接訓練的模型;缺哪個後端(例如沒裝 CatBoost)就自動略過,不會中斷:
顯示程式碼
model_templates = q.get_models()目前可取得的模型如下表,涵蓋梯度提升樹到深度學習:
| 模型 | 類型 | 適用情境 |
|---|---|---|
| LGBModel | LightGBM 梯度提升樹 | 速度快、表格特徵首選,本文表現最佳 |
| XGBModel | XGBoost 梯度提升樹 | 與 LightGBM 同類,調參空間大 |
| CatBoostModel | CatBoost 梯度提升樹 | 對類別特徵與過擬合較穩健 |
| DEnsmbleModel | 雙重整體(Double Ensemble) | 多模型整合,降低單一模型偏誤 |
| LinearModel | 線性模型 | 當基準線,解釋性高 |
| TabnetModel | TabNet 深度學習 | 表格資料的注意力網路 |
| DNNModel | 深度神經網路 | 需較多資料與算力 |
| SFMModel | State Frequency Memory | 把序列拆成不同頻率成分學習 |
訓練時把資料切成樣本內(2020 年以前)與樣本外(2020 年以後),逐一訓練並隨手存檔,避免 RAM 中途爆掉得從頭來過:
顯示程式碼
import os
import gc
import pickle
import numpy as np
model_templates = q.get_models()
is_train = features.index.get_level_values('datetime') < '2020-01-01'
model_path = './models.pkl'
models = {}
if os.path.isfile(model_path):
with open(model_path, 'rb') as f:
models = pickle.load(f)
for name, Model in model_templates.items():
if name in models or name == 'DNNModel':
continue
X_train = features.loc[is_train]
y_train = labels.loc[is_train]
# 清掉 inf / NaN 後再訓練,避免某些模型報錯
ok = X_train.replace([np.inf, -np.inf], np.nan).notna().all(axis=1) \
& y_train.replace([np.inf, -np.inf], np.nan).notna()
model = Model()
model.fit(X_train.loc[ok], y_train.loc[ok])
models[name] = model
with open(model_path, 'wb') as f:
pickle.dump(models, f)
gc.collect()每個模型在 fit() 時會自動從訓練集切出驗證集,用來監控過擬合,這也是用 finlab 包裝後省事的地方。
樣本外回測:比較各模型的選股能力
把訓練好的模型套到 2020 年以後的樣本外資料,產生預測分數,再用 finlab 的 sim() 月頻回測。下面對每個模型都選預測分數最高的 20 檔股票:
顯示程式碼
from finlab.backtest import sim
from finlab import data
import matplotlib.pyplot as plt
ys = {name: model.predict(features[~is_train]) for name, model in models.items()}
reports = {}
for name, y in ys.items():
with data.universe('TSE_OTC'):
close = data.get('price:收盤價')
report = sim(y[close.notna()].is_largest(20), resample='M', upload=False)
reports[name] = report
report.creturn.plot(label=name)
plt.legend()
plt.show()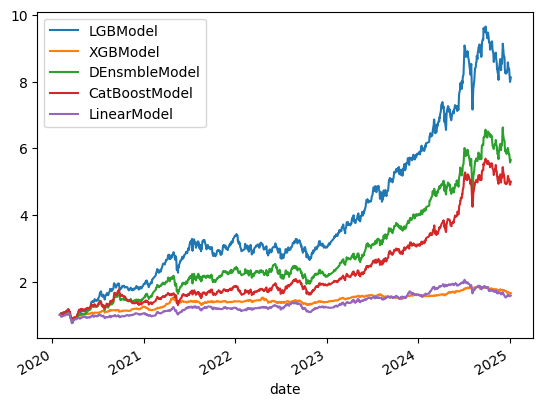
不同模型的選股能力有明顯差距。把每個模型的回測指標整理成表後可以看到,梯度提升樹這一類(以 LGBModel 為代表)在這段樣本外期間的表現相對突出:
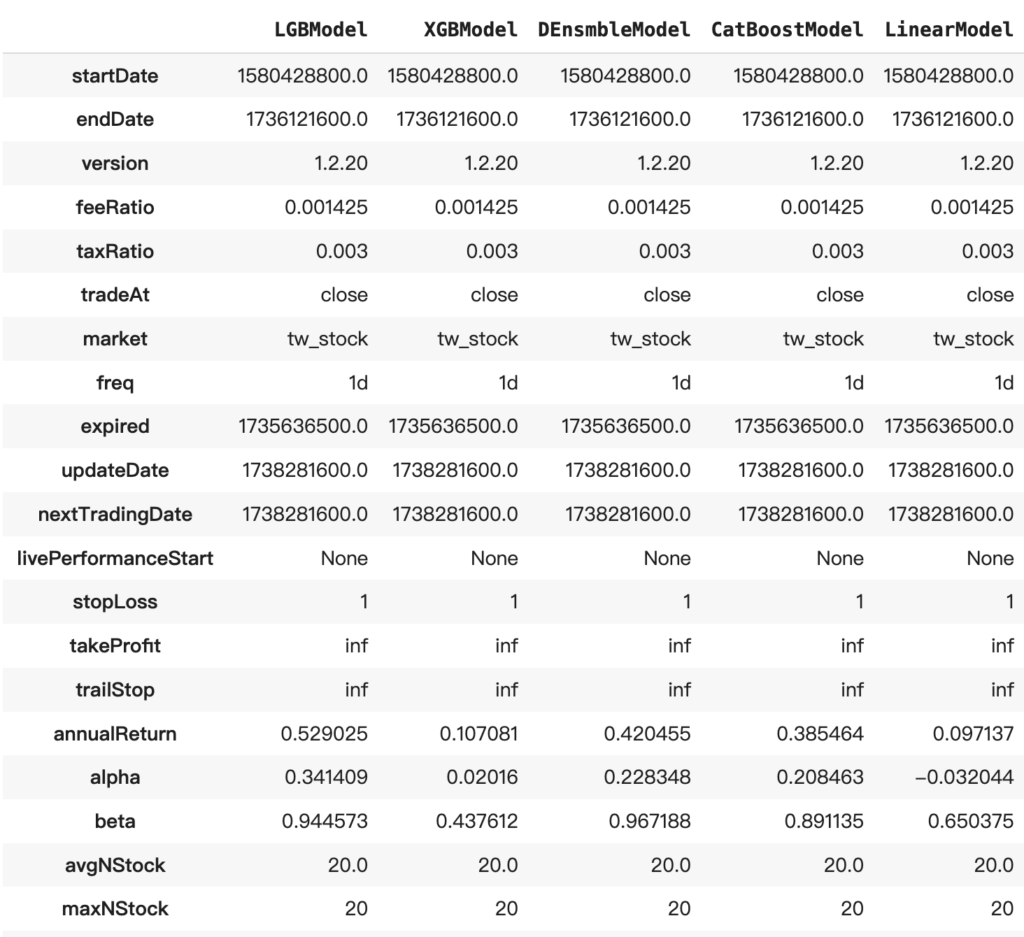
以表現最好的 LGBModel 為例,再加上兩道實務濾網:20 日均量大於 20 萬股(避免買到回測買得到、實單買不到的低流動性股),以及股價站上近 10 日高點(順勢),縮到只選 10 檔:
顯示程式碼
y = ys['LGBModel']
with data.universe('TSE_OTC'):
close = data.get('price:收盤價')
vol = data.get('price:成交股數')
liquid = vol.average(20) > 200_000 # 流動性濾網
momentum = close >= close.rolling(10).max() # 動能濾網
position = y[liquid & momentum].is_largest(10)
report = sim(position, resample='M', upload=False)
report.display()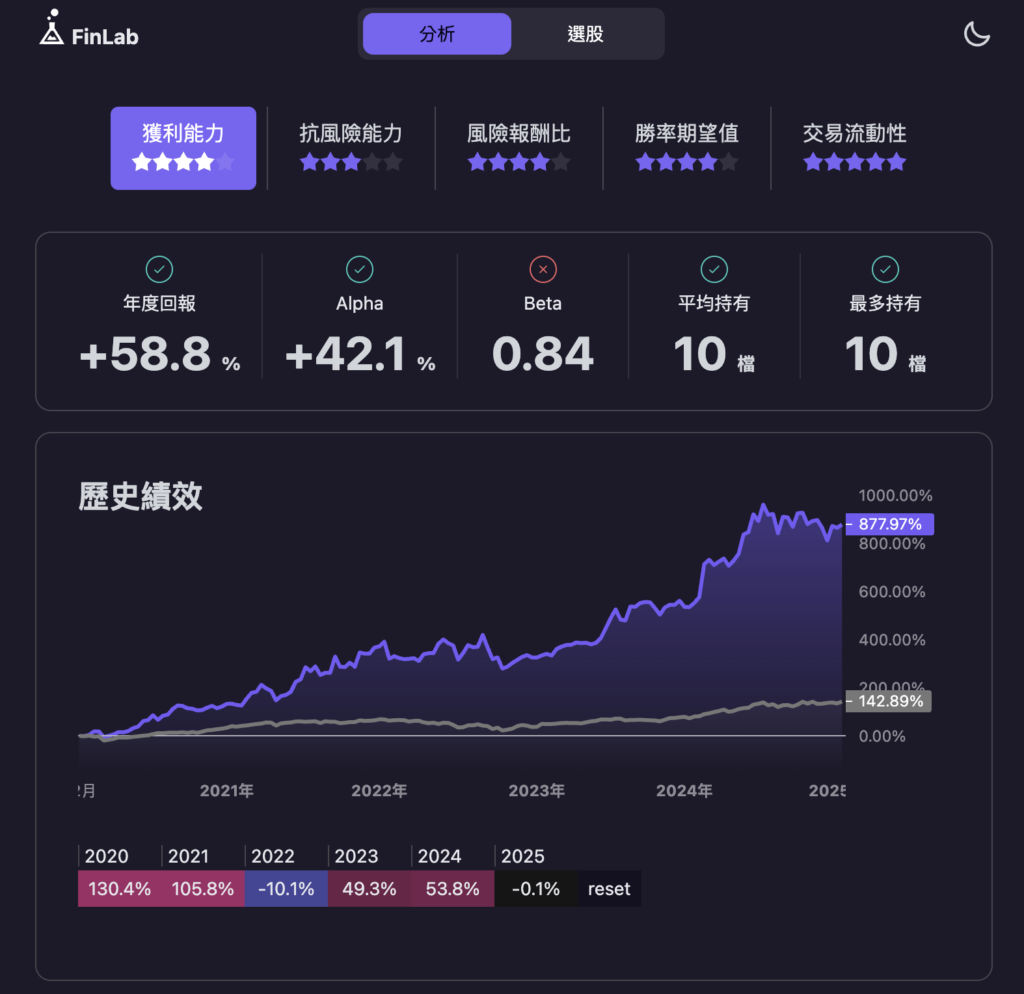
完整的權益曲線、年化報酬、最大回撤與夏普值都在上面的回測報告裡。把這段程式碼當成起點,換特徵、換濾網、換再平衡頻率,都能延伸出自己的版本。
回測方法與限制
AI 模型最容易給人「指標漂亮、方法很薄」的錯覺,所以把這個範例的設定與沒做到的地方一次講清楚:
- 交易成本:
sim()預設已內扣台股手續費 0.1425% 與賣出證交稅 0.3%,月頻再平衡的成本已反映在績效裡。 - 股票池與流動性:宇宙為上市加上櫃(
TSE_OTC);最後一版策略加了 20 日均量大於 20 萬股的流動性門檻,但未估算策略容量(資金規模拉大後的衝擊成本未計)。 - 樣本內外:2020 年以前訓練、2020 年以後測試,屬於單一切點的樣本外,沒有做滾動重訓練;參數(選 10 檔、近 10 日高、月頻)未做敏感度掃描。
- 前視偏差:特徵與標籤都用
combine對齊索引,標籤是「未來 2 期報酬」,預測時只用樣本外特徵,沒有用到未來資料。 - 基準對照:本文聚焦各模型之間的相對比較,未與含息 0050 做同口徑對照;想看「贏不贏大盤」的嚴謹比較,可參考〈台股選股回測:單因子全輸 0050、複合策略風險調整後勝出〉的基準口徑。
- 模型的時運:AI 模型對市場結構(regime)敏感,這幾個月的整體表現偏弱,不代表方法失效,但也提醒:樣本外亮眼不等於未來保證,實單前務必自行重跑與驗證。
這段「沒做到什麼」比任何一個漂亮數字都重要,它決定了你能不能信任這個結果。
Qlib 和 finlab 怎麼選
| 面向 | Qlib | finlab |
|---|---|---|
| 定位 | 通用 ML 量化研究框架 | 台股資料與回測為核心 |
| 內建資料 | 中、美股 | 台股(價量、財報、籌碼、月營收等) |
| 強項 | 模型多樣、Workflow、訓練管理 | 台股資料齊全、sim() 回測、可用 AI 對話操作 |
| 台股使用 | 需自行接資料與市場規則 | 原生支援,AI 輔助安裝流程 即可 |
兩者並不互斥:Qlib 提供模型與特徵的肩膀,finlab 補上台股資料與回測,用 finlab[qlib] 接起來就能在台股上享受 Qlib 的研究能力。想完整理解量化研究的全貌,可以從量化交易完整指南入門。
適合誰、不適合誰
適合:想用機器學習做選股研究、又不想從零打造工程框架的人;已熟悉 Python、想站在現成模型與特徵肩膀上的人。
不適合:只想要一鍵買賣訊號、不打算碰程式與模型訓練的人,這類需求用現成的台股選股策略或 AI 對話式操作會更省事。Qlib 的學習曲線偏陡、框架也較重,如果你的目標只是快速驗證一個選股想法,建議先用 finlab 把策略跑出來、確認方向有效,再回頭考慮要不要導入 Qlib 的 ML 流程。
常見問題(FAQ)
Qlib 是什麼?
Qlib 是微軟開源的 AI 量化投資研究平台,用 Python 把資料、特徵、建模、回測到下單決策整合成一條龍流程,內建十餘種機器學習與深度學習選股模型範例,定位是給研究者用的 AI 量化骨架。
Qlib 可以用在台股嗎?
可以,但 Qlib 本身沒有台股資料。透過 finlab 的 finlab.ml.qlib,用 q.dump() 把台股資料轉成 Qlib 格式、q.init() 套用台股市場規則,就能在台股上使用 Qlib 的 Alpha158/Alpha360 特徵與內建模型。
finlab[qlib] 怎麼安裝?
執行 pip install 'finlab[qlib]' 即可一次帶起 finlab 與 Qlib。模型後端(LightGBM、XGBoost、CatBoost)與 TA-Lib 是選用的,需要時再各自安裝。
Alpha158 和 Alpha360 差在哪?需要多少記憶體?
Alpha158 是 158 個價量特徵,是日常研究主力;Alpha360 是 360 個,更細但展開後常需上百 GB 記憶體。即使是 Alpha158,全台股日頻也很吃資源,把頻率改成週頻可省約 80% 資料量,50GB RAM 環境較能負荷。
q.get_models() 有哪些模型?
涵蓋 LGBModel(LightGBM)、XGBModel(XGBoost)、CatBoostModel、DEnsmbleModel、LinearModel、TabnetModel、DNNModel、SFMModel。沒安裝對應後端的模型會自動被略過,不影響其他模型訓練。
為什麼要透過 finlab 使用 Qlib,而不是單獨用 Qlib?
Qlib 框架相對封閉,預設不含台股,也不容易和 sklearn、LightGBM 等生態無縫銜接。finlab 一方面補上台股資料與市場規則,一方面把特徵生成、模型訓練、回測接到自己的資料與 sim() 回測引擎,研究流程也能跟既有的台股因子策略共用同一套資料來源。
這個 AI 選股策略可以照抄拿去實單嗎?
不建議照抄就上。範例是單一切點的樣本外示範,沒有做容量估計、滑價假設與滾動重訓練,AI 模型又對市場結構敏感。把它當研究起點,自行重跑、加上停損與資金控管等風控機制後再評估,並先用小額或模擬部位驗證一段時間。
延伸閱讀
- 量化交易完整指南
- 程式交易是什麼?教學、優缺點與可跑的 Python 回測
- Information Coefficient(IC):用台股真實 IC 驗證因子
- 機器學習真的無法預測股價嗎?用 AI 產生交易訊號的正確方法
- 用深度學習 LSTM 解析 K 線圖,實作台股股價預測
- 用 Python 計算 158 種常見技術指標(TA-Lib 教學)
- AI 量化研究:用提示詞把選股想法跑成可回測策略
- Python 股票選股與回測教學:5 分鐘用 finlab 挑股票做回測
- AI 量化實測:Qwen 3 自動寫策略,12 次迭代結果
投資警語:本文為教學與研究分享,不構成投資建議。回測為歷史資料下的結果,不保證未來績效;AI 模型可能因市場結構改變而失效,實際投入前請自行驗證並控制風險。
最後更新:2026-06|回測區間:訓練 ~2019、樣本外 2020 年起|作者:FinLab 量化研究團隊(經量化研究員審閱)
FinLab AI
想建立自己的策略?
用自然語言描述你的選股想法,AI 自動驗證、回測、給你答案
免費開始