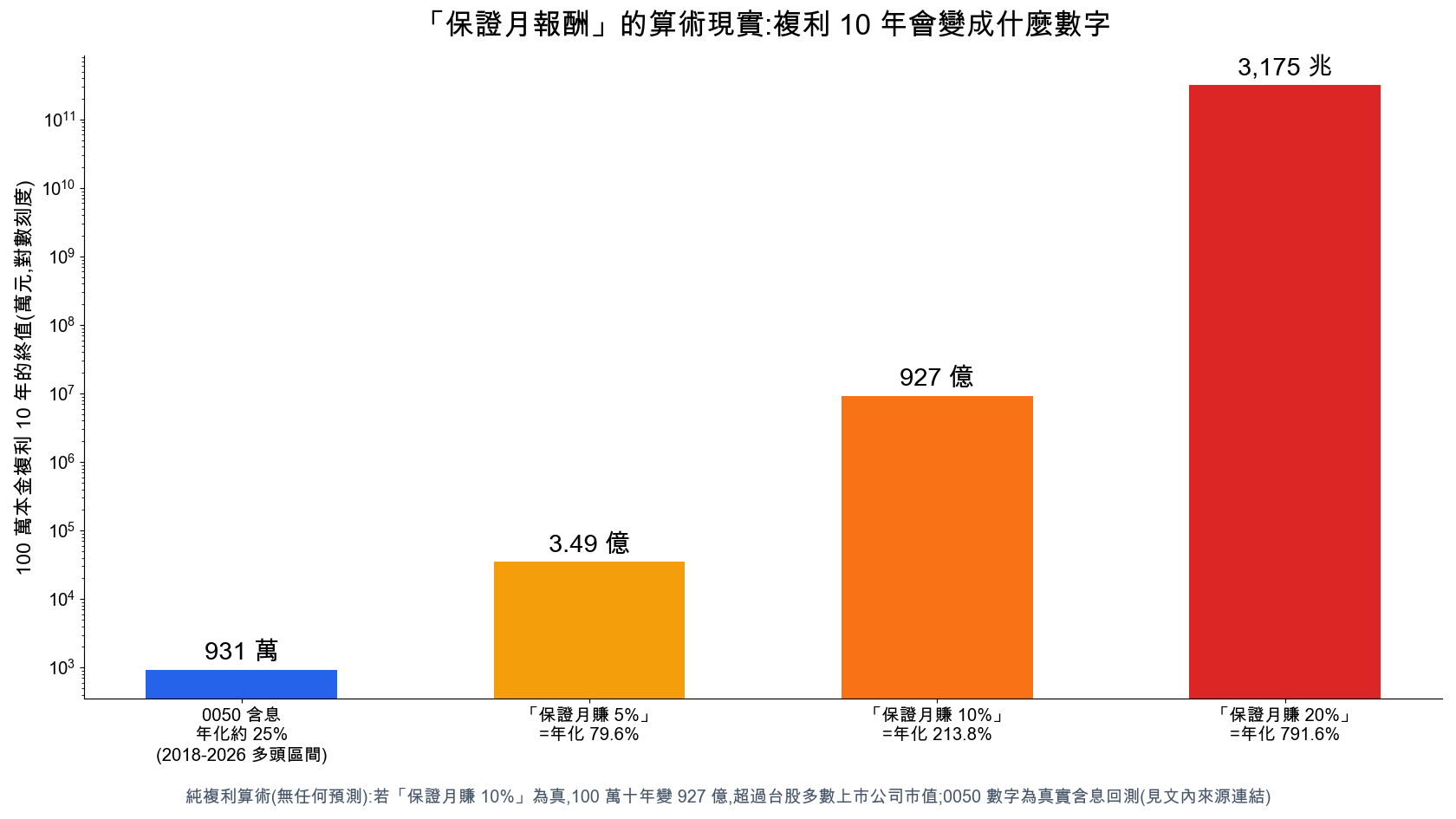
接下來為期幾天,將為大家打下 python 更深刻的基礎,適合剛學 python,但是對 pandas 不太熟的讀者,這次我們就來把所有的股票代號給爬下來,並整理一番喔!
Python 真的很厲害~可以用少少的語法達到非常多的功能 我覺得 python 搭配 excel 是沒有必要的,直接使用 python 替代 excel 才是最佳的方式!

這禮拜終於比較悠閒一點,開始寫 blog 了,目前主要還是繼續培養大家的 python 實力為主,因為有一些同學說明課程有些地方跳的比較快,其實可以參考一些網路上免費的 python 課程來補齊,不過此 blog 也會隨時補充一些實用的功能,或是簡單的 python 常用的 package 和語法,幫助大家熟練 python。
今天要做的就是取得上市櫃股票代號與分類,首先,我們想要爬的網頁是: http://isin.twse.com.tw/isin/C_public.jsp?strMode=2
其中 strMode=2 就是上市,而 strMode=4 就是上櫃,接下來我們就來將此網頁下載下來吧!
爬取網頁
顯示程式碼
import requests
res = requests.get("http://isin.twse.com.tw/isin/C_public.jsp?strMode=2")其中,我們使用了常用的 package 叫做 requests,可以模擬網頁瀏覽器,其中 requests.get 就是模擬我們連到該網頁,下載網頁的原始碼~
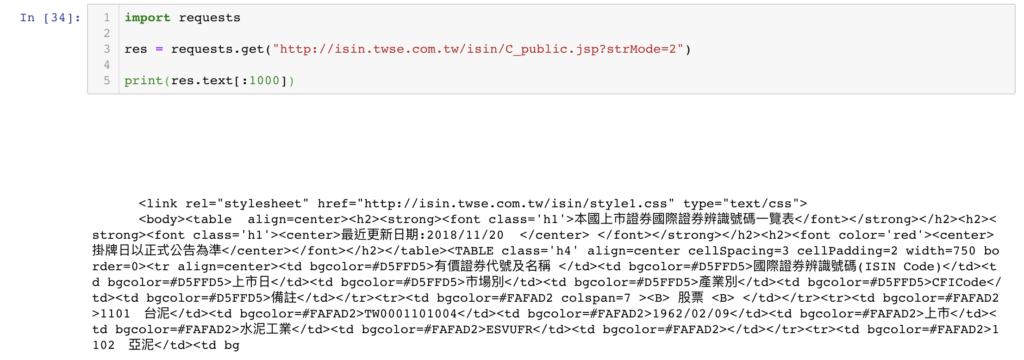
將網頁轉成 DataFrame
我們用了上述的程式碼,就可以獲得該網頁的原始碼,瀏覽器就是用這些原始碼渲染成網頁讓您操作的,我們可以從網頁原始碼中萃取出表格,產生 DataFrame
顯示程式碼
import pandas as pd
df = pd.read_html(res.text)[0]
df第一行:pd 就是我們萃取原始碼的 package,全名叫做 pandas,你可以想像 pandas 就是 python 界的 excel 軟體,可以操作各式各樣的表格,進行運算。
第三行:我們可以利用 pd.read_html 將我們剛剛爬取到的網頁原始碼 res.text 中的表格給萃取出來,而其中 [0] 是指說,萃取出來的可能有很多張表格,我們只需要第一張表格即可~
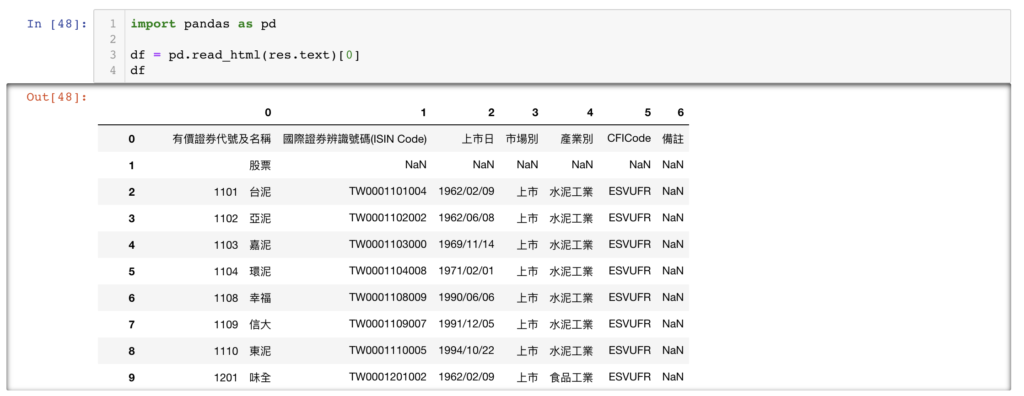
整理資料 1 整理 column 名稱
可以看到上圖,目前 column 名稱只是 1、2、3、4,一些數字而已,但我們希望它們是有意義的文字,而我們又可以發現,其中第一行 row,就是我們所需要的,所以,我們可以將第一行變成 columns 的名稱:
顯示程式碼
# 設定column名稱
df.columns = df.iloc[0]
# 刪除第一行
df = df.iloc[1:]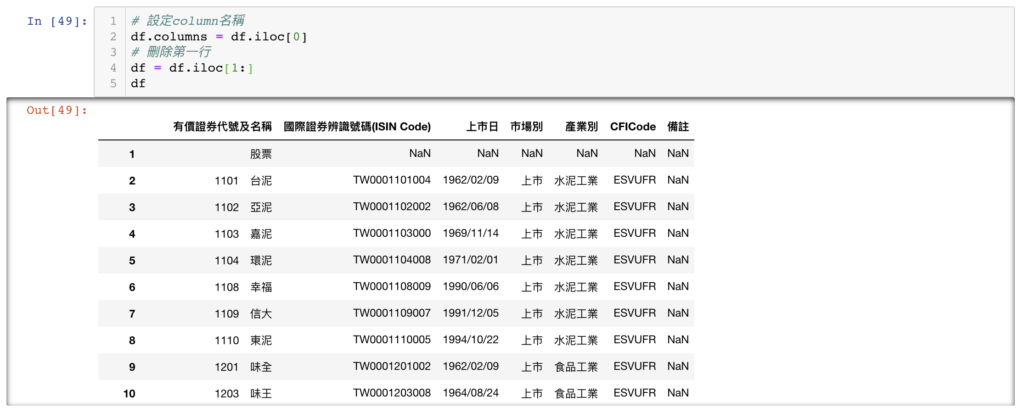
整理資料 2 刪除冗餘行列
接下來我們發現整理好 column 名稱後,還是有一些 row 很明顯是多餘的,我們必須要把它們刪除,刪除的方式,最簡單就是使用 dropna,並且設定當 row 或是 column 的 NaN 數量大於某個數字(例如 3)時,我們就將該 column 或 row 移除:
顯示程式碼
# 先移除row,再移除column,超過三個NaN則移除
df = df.dropna(thresh=3, axis=0).dropna(thresh=3, axis=1)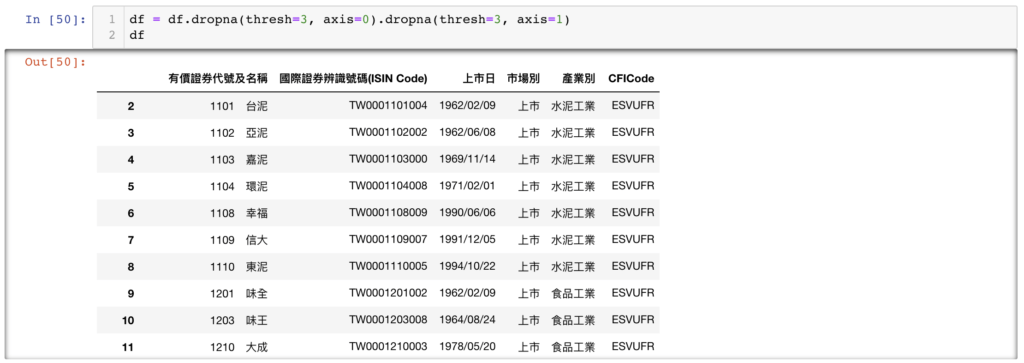
設定 index
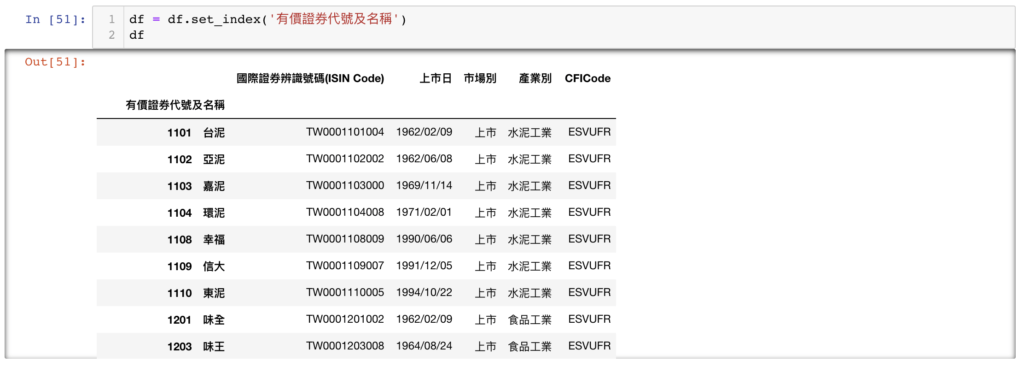
我們可以看到 index 目前也是數字,我們希望它是股票代號,則可以使用
顯示程式碼
df = df.set_index('有價證券代號及名稱')即可!
由今天的練習,我們學到了使用 requests 來模擬瀏覽器,用 pandas 解析出網頁中的 table,並且利用 pandas 中的功能,將 table 作整理!
博士班口試結束了,接下來我會盡力開始維持 blog 正常出貨!也希望能提供更多的選股、程式上的教學!
爬下完整的股票清單後,下一步通常是接上價量與財報資料來篩選標的,想看這套流程如何延伸成完整的策略開發,可以參考量化交易完整指南。
本文僅供教學與研究參考,不構成投資建議。過去績效不代表未來表現,投資一定有風險,請審慎評估自身風險承受能力。
FinLab AI
想建立自己的策略?
用自然語言描述你的選股想法,AI 自動驗證、回測、給你答案
免費開始