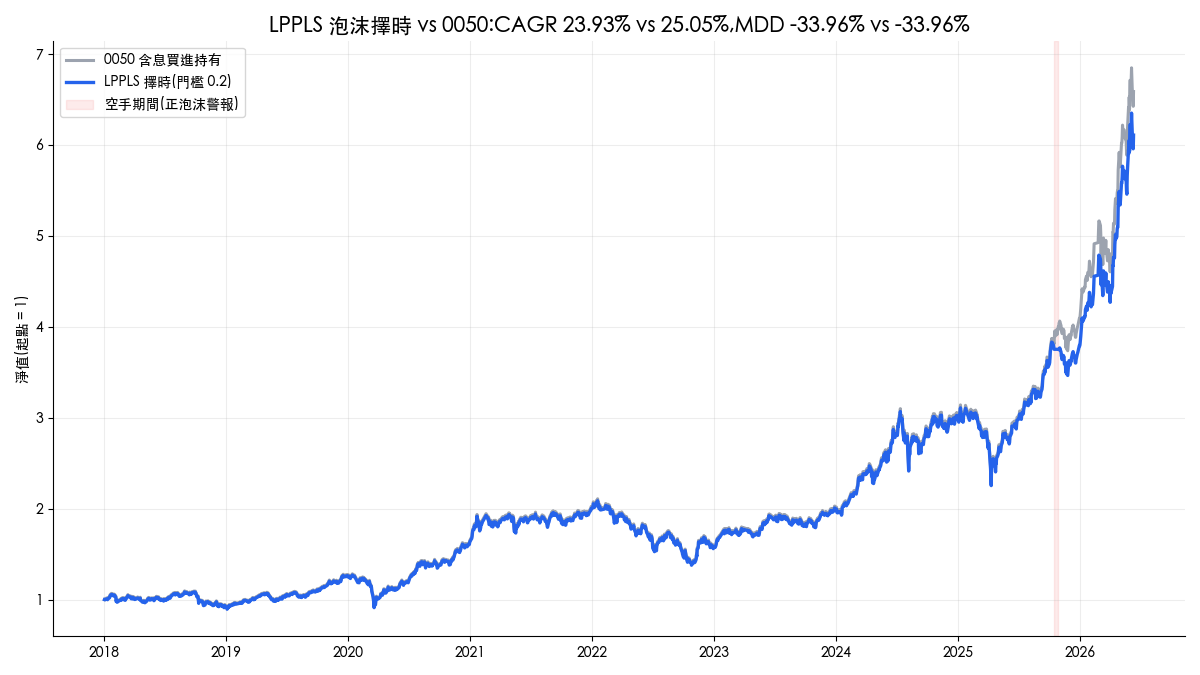
美國科技業近期大裁員,媒體上充滿失業率的話題,美國失業率的指標要去哪裡抓? 本篇文章介紹如何使用「美國勞動部統計局」的 API 來撈取美國總經數據,把總經分析戰線擴充到國際市場。
API 註冊
美國勞動部統計局有開放 Python API 給開發者使用,建議去用信箱註冊一個 API 帳號,不然未註冊月戶每天只有25次取資料的權限,實在是很少,申請過後每日就能有 500 次Request。 註冊只要填信箱,送出後就會寄出 API key 的生效確認信,點擊確認後即可生效。
API 規範
建議使用 API Version 2.0,權限開比較多。更多常見問題可見 Q&A。 **How is API Version 2.0 different from Version 1.0?**API Version 2.0 requires registration, and it offers greater query limits. It also allows users to request net and percent changes and series description information. See below for more details.
| Service | Version 2.0 (Registered) | Version 1.0 (Unregistered) |
|---|---|---|
| Daily query limit | 500 | 25 |
| Series per query limit | 50 | 25 |
| Years per query limit | 20 | 10 |
| Request rate limit | 50 requests per 10 seconds | 50 requests per 10 seconds |
| Net/Percent Changes | Yes | No |
| Optional annual averages | Yes | No |
| Series description information (catalog) | Yes | No |
美國勞動部統計局API版本差異
如何使用 API ?
詳見開發者文件範例,以下舉爬取「失業率」當例子: 首先要傳入payload內的參數設定,seriesid 為 指標代號,常用指標代號可在官網相關頁面查詢或透過 API 取得常用代號列表。 startyear 為資料開始年度。 endyear 為資料結束年度。 registrationkey 為 api_key,有註冊的話要記得填喔
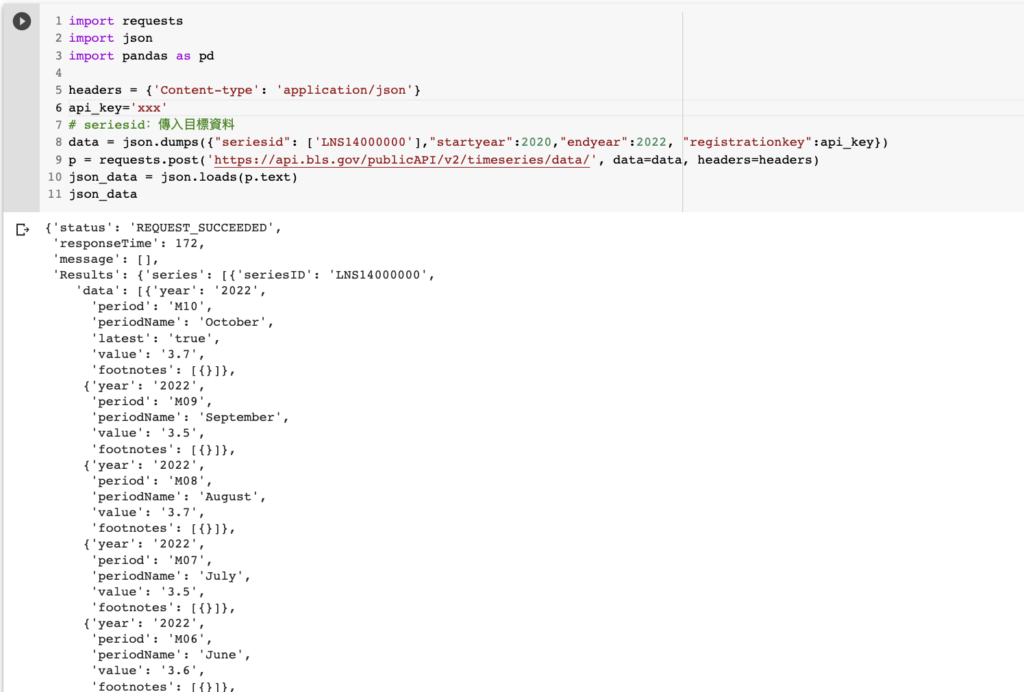
失業率response
就這麼簡單將 json 檔下載下來,就可以取得時間序列資料。
失業率發布日
原始資料有一個問題是無法直接取得資料公告時間,只能知道數值是哪一個月份,以失業率來說,美國官方會預告發佈時間,原則上失業率是每個月第一個星期五,但偶爾會因為假日或其他因素遞延。
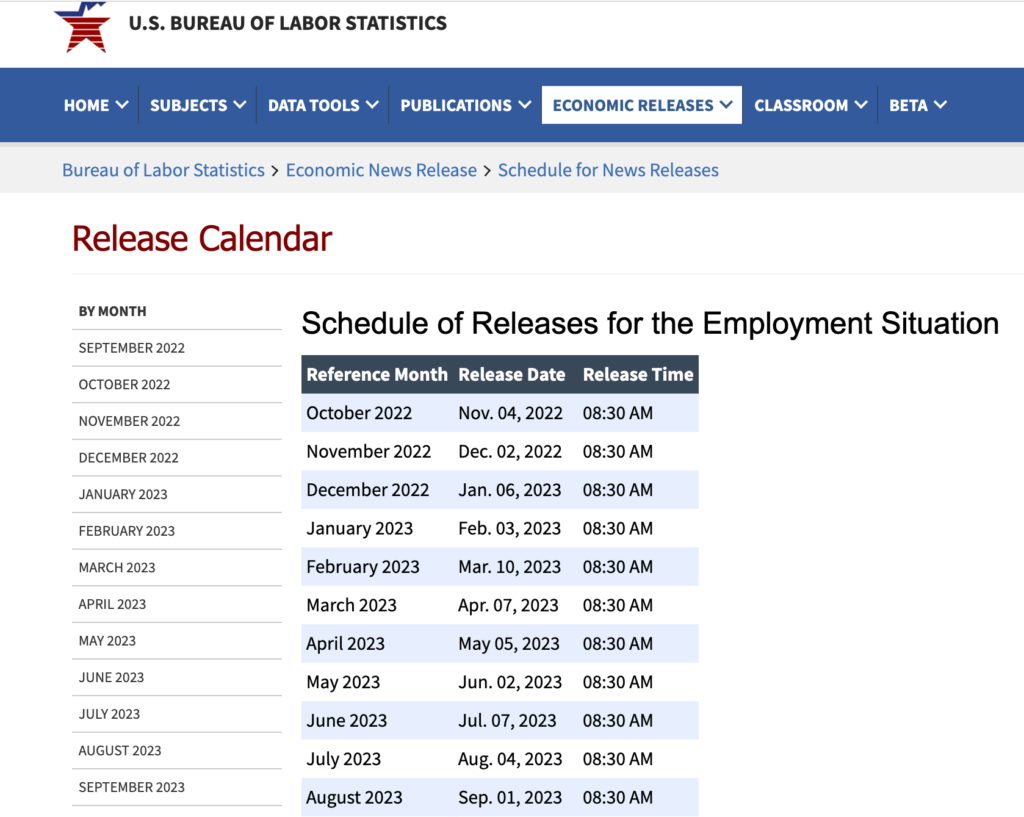
勞動部統計局就業數據預計發布日
為避免使用到未來資料,我們使用每月10日當安全數值。以下為Python爬蟲完整程式,主要加上處理發布日期的部分,發便未來回測使用。
顯示程式碼
import requests
import json
import pandas as pd
def crawl_data(start_year, end_year, api_key='xxxx'):
headers = {'Content-type': 'application/json'}
# seriesid:傳入目標資料
data = json.dumps({"seriesid": ['LNS14000000'],"startyear":start_year, "endyear":end_year, "registrationkey":api_key})
p = requests.post('https://api.bls.gov/publicAPI/v2/timeseries/data/', data=data, headers=headers)
json_data = json.loads(p.text)
# 將資料轉成dataframe
df = pd.DataFrame(json_data['Results']['series'][0]['data'])
# 將資料日期轉成公告日,當月失業率在下一個月才公告
latest_year = int(df['year'].iloc[0])
latest_month = int(df['period'].iloc[0].replace('M',''))
start_year = int(df['year'].iloc[-1])
start_month = int(df['period'].iloc[-1].replace('M',''))
def process_date(year,month):
if month == 12:
month = 1
year += 1
else:
month += 1
return year,month
latest_year, latest_month = process_date(latest_year, latest_month)
start_year, start_month = process_date(start_year, start_month)
issue_date = pd.date_range(f'{start_year}-{start_month}-1', f'{latest_year}-{latest_month}-1',
freq='MS') + pd.tseries.offsets.DateOffset(days=9)
df_new = pd.DataFrame({'value': df['value'].values[::-1]}, index=issue_date)
df_new['value'] = df_new['value'].astype(float)
df_new.index.name = 'date'
return df_new
df = crawl_data('2015', '2023')
df小結
colab範例檔 美國勞動部統計局有許多非常重要的資料,除了就業相關數據如失業率、非農、就業津貼,還有物價指數CPI、PPI,都能幫助我們後續做分析,趕緊學會該 API 的使用法則,打造總經分析武器庫。 想知道美國失業率如何應用在美國指數的擇時回測嗎?可以繼續看「用Python回測總經指標(2)|美國失業率 vs S&P 500指數」踏入更豐富的數據世界。
延伸閱讀
投資警語:本文僅供教學參考,不構成投資建議。過去績效不代表未來表現,投資有風險。
FinLab AI
想建立自己的策略?
用自然語言描述你的選股想法,AI 自動驗證、回測、給你答案
免費開始