上一篇的 Python 教學中,我們學會了怎麼用爬蟲抓取財報,但是爬完的資料要怎麼運用呢?這篇會教大家如何利用一個實用的 Pyton package:Pandas,整理爬下來的資料,並且輕鬆運用 Python 選股!
上一篇有點不好意思,好像有兩個 package 沒有 import,下次發現的話,可以在下方留言告訴我,我會盡快更正。
今天這篇的前置作業,請參考連結把當中的 function 給 copy 過來,然後就開始吧!
資料處理
首先,我們要先使用這個 function,可以直接在 jupyter 視窗內輸入,來取得爬取今天的主角:”營益分析彙總表”
利用上次的爬蟲取得資料
顯示程式碼
df = financial_statement(107, 2, '營益分析彙總表')
df第一行,我們將 “營益分析彙總表” 儲存在 df 這個變數之中, 第二行,我們希望將 df 給顯示出來,看一下它長什麼樣子 第二行的功能是只有在 jupyter 這個 IDE 才看的到喔~假如是寫在 python script 的話,就要用 print(df) 。 假如一切 OK 就會是以下的樣子:
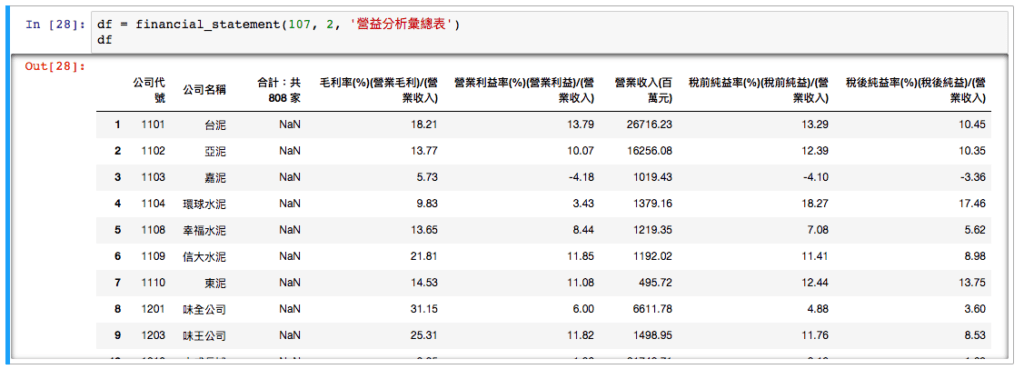
我們觀察一下這張表,有一行真的詭異:”合計:共 808 家” ,這行完全沒有任何可以用的資料,所以我們將它刪除:
刪除其中一行
顯示程式碼
df = df.drop(['合計:共 808 家'], axis=1)接下來我們發現 index (每一列)的命名很怪,怎麼用 1,2,3… 來命名呢,應該要用公司名稱!? 我們將股票的名稱當成新的 index:
將 index 換成公司名稱
顯示程式碼
df = df.set_index(['公司名稱'])最後一步,我們希望資料欄位中,所有的元素都是 float ,所以要做一次轉換:
轉換成數值
顯示程式碼
df = df.astype(float)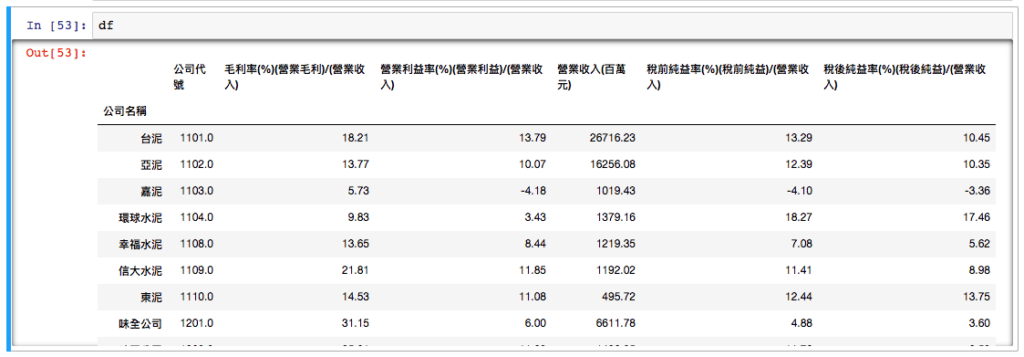
資料處理一行版
這樣就沒問題了!其實有個更快速的寫法,將以上三件事情寫成一行:
一行直接處理
顯示程式碼
df = df.drop(['合計:共 808 家'], axis=1).set_index(['公司名稱']).astype(float)這樣就可以一次處理好!
簡單的取出行列:
我想單選出毛利率:
取得毛利率
顯示程式碼
df['毛利率(%)(營業毛利)/(營業收入)']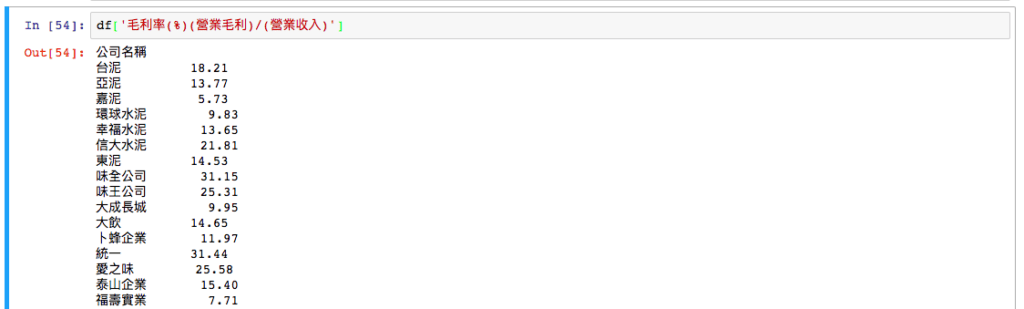
假如今天我只想看 台積電 表現如何:
取得台積電資料
顯示程式碼
df.loc['台積電']取每一欄,跟取每一列,語法不太一樣喔!要小小注意一下。

假如我想同時看 台積電 跟 聯發科:
取得 TSMC 跟 MTK 的資料
顯示程式碼
df.loc[['台積電', '聯發科']]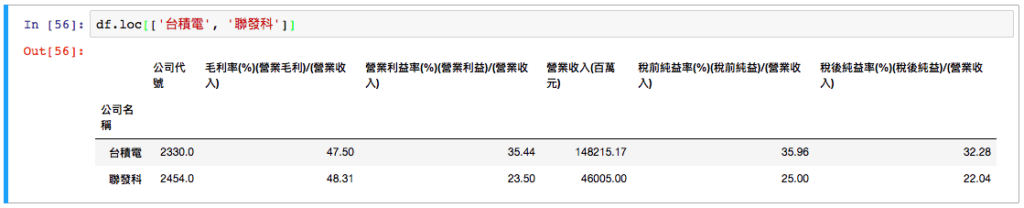
數值分析
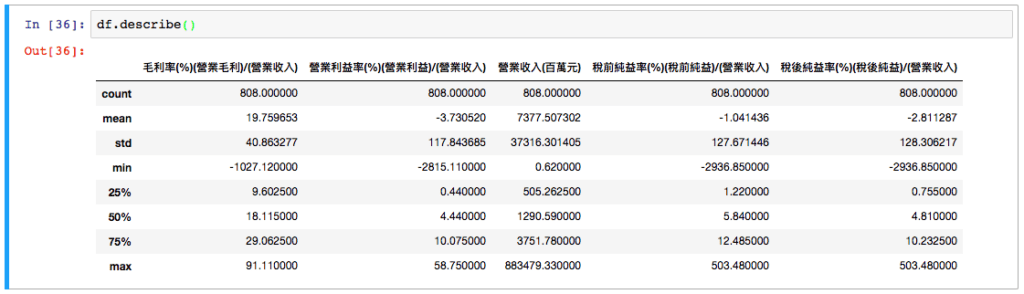
接下來我們稍微分析一下這個表中的數字: 數值分析
顯示程式碼
df.describe()這樣簡單一行,就可以得到每一欄的數值分析,當初我知道這個 df.describe() 也覺得很神。
毛利率分佈圖
只要簡單一行,我們就可以看到全台灣的上市公司,毛利率分佈圖:
顯示程式碼
%matplotlib inline
df['毛利率(%)(營業毛利)/(營業收入)'].hist(bins=range(-100,100))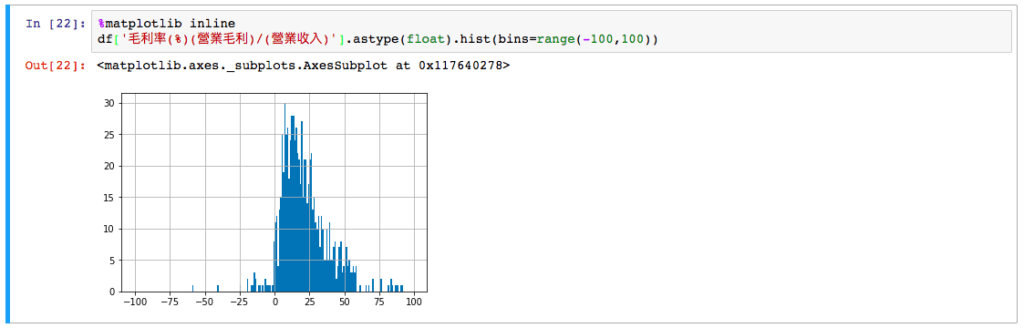
選股
選股也很簡單,只要寫成以下條件:
顯示程式碼
cond1 = df['毛利率(%)(營業毛利)/(營業收入)'].astype(float) > 20
cond2 = df['營業利益率(%)(營業利益)/(營業收入)'].astype(float) > 5就是說 第一個欄位:毛利率,我們希望找出大於 20 的 股票 另外呢 第二個欄位:營業利益率,我們希望找出大於 5 的 股票
那我們就可以用這兩個條件來選股:
顯示程式碼
df[cond1 & cond2]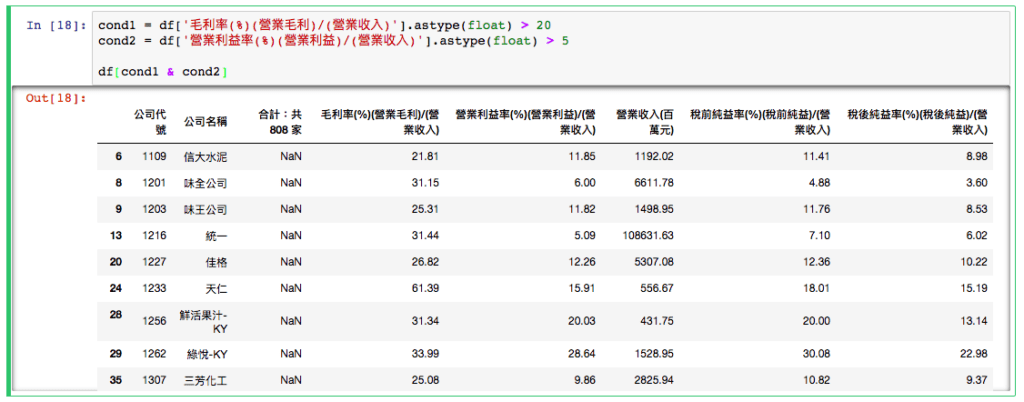
搭啦!其實外面的選股軟體也就這樣而已啦!還收費這麼貴 XDD 如果你覺得觀賞這個 blog 有點收穫,記得存到我的最愛定期觀看喔!我每個禮拜都會有一些更新。
延伸閱讀
- Python 量化交易完整教學
- 超簡單台股每日爬蟲教學:15 行 Python 下載股價篩低本益比
- 產業資料庫基礎應用:用 Pandas 客製化台股產業分類
- Pandas 魔法筆記:財經數據處理常用招式總覽
- 台股怎麼選股?四大面向完整指南
投資警語:本文僅供教學參考,不構成投資建議。過去績效不代表未來表現,投資有風險。
FinLab AI
想建立自己的策略?
用自然語言描述你的選股想法,AI 自動驗證、回測、給你答案
免費開始